





Frank M. Shipman III, Catherine C. Marshall
Department of Computer Science
Texas A&M; University
College Station, TX 77843-3112
(409) 862 - 3216
{shipman, marshall}@cs.tamu.edu
Thomas P. Moran
Xerox Palo Alto Research Center
3333 Coyote Hill Road
Palo Alto, CA 94304
(415) 812 - 4351
moran@parc.xerox.com
Many kinds of software, ranging from operating systems to graphics editors to collaboration substrates to hypermedia applications, provide users with two or two-and-a-half dimensional spaces in which they can organize information in the form of graphical objects. These manipulable objects include icons or other visual symbols representing larger pieces of information, as well as complete chunks of information. People tend to follow certain conventions when they lay out these objects to indicate relationships among them. We are investigating methods of recognizing such implicit spatial structure and using it to support users' activities.
We first examined the kinds of spatial layouts that people produce in both computational and noncomputational media. Based on these results, and the results of analogous studies of the way people organize materials in their physical environments [4][6][7], we developed a "spatial parser" to recognize common structures. The parser is built to be portable and extensible so that it can be added to new systems or augmented to recognize new kinds of structures with little effort. We integrated the parser with VIKI [11], a spatial hypertext system, to explore the use of recognized structure. VIKI currently includes two types of support based on the parser. First, VIKI provides users with ready access to implicit structures. Second, at user initiative, VIKI suggests formally represented structures based on the implicit structure.
The next section summarizes our study of user-constructed spatial arrangements and the conventions we found. We then describe the architecture developed for recognizing these common spatial structures. Finally, we discuss the application of structure recognition to support users performing information management and analysis tasks in VIKI.
Experiences with the use of Aquanet [9] led us to recognize the importance users place on implicit spatial structures. This realization prompted us to perform a survey of spatial structures people created in diverse hypermedia systems and in non-computational settings (such as notecards and Post-its stuck on a wall) [10].
As part of the survey, we analyzed nine layouts, each the result of a long-term information management or analysis task. Three of the layouts were created in NoteCards [2], one in the Virtual Notebook System [14], and three in Aquanet [8]. The two non-computational layouts in our survey involved wall-sized arrangements of 3" x 5" cards, Post-its, and other pieces of paper. Table 1 shows the task, source, and number of objects for each of these layouts.
TABLE 1:Spatial layout task, source, and data characteristics.
To perform the analysis, we introduce three analytic abstractions. The first is the notion of graphical information objects already discussed. Also, we use the idea of object type. Here, type is used to reflect an object's distinguishing visual characteristics and functional role within a given spatial layout. We also use the idea of spatial structure, which is a perceptually distinct group of objects. Table 1 includes the number of object types identified in our analysis.
Following this analytic framework, we encoded the data in a canonical form which recorded spatial and visual aspects of the graphical information objects, including the relative planar location and the extent of each object. Each object was also assigned a type based on its system type (if it had one) and distinguishing visual characteristics (for example, font or color). Discussions with the people who created the layouts helped us to understand the intended structures in each example and their meaning. We discovered that a small set of common structures, like stacks and lists, were common across the layouts, even though they were created in a variety of systems and in service of different tasks.
Analysis of the content and function of the objects used in these structures revealed that people used spatial layouts to represent different types of relationships among constituents. First, spatial structure was used as a means of categorization or to build up sets. Second, spatial proximity was used to indicate specific relationships among objects or among types of objects. Finally, spatial arrangement was in some instances dictated by the way in which objects were used together in a task.
The following two examples, one computational, one non-computational, illustrate the kinds of conventional structures we found, and preview the issues that arise in developing heuristics for recognizing these structures and using them to support users' activities.
FIGURE 1: Example of spatial layout from Aquanet.
It is readily evident to human perception that there is a significant amount of structure in the spatial layout in Figure 1. Yet very little of this structure is expressed in such a way that it is accessible to the system in which the layout was created (even though the system provided users with a mechanism for expressing just such structure).
FIGURE 2:Close-up of structure with description.
Figure 2 is a close-up of one of the structures in Figure 1. The arrangement includes a list with six similar elements (of type subtopic); it is a good example of the kind of structure people use to express categories or sets. This list is part of a higher-level structure that includes the list and its heading, which is of a different type. We refer to this kind of structure (one consisting of a regular pattern of different object types) as a composite. The list of annotations on the right side of the list refers to a portion of the list. Unlike the rest of the structure, without examining contents, this sort of reference is more idiosyncratic and remains ambiguous to human perception. In our analysis of the layouts for common structures, we resolved such ambiguities by looking at textual content and talking to the original authors.
Referring back to Figure 1, we can also see that this list is part of a larger structure of six such lists, some of which are annotated, arranged horizontally across the space. It is a structure constructed in service of the larger activity of writing a paper.
Figure 3 shows a diagram of one of the non-computational layouts from our survey. This layout consists of around two hundred eighty 3"x5" cards, Post-Its, and other paper covering a good-sized wall. The arrangement was used to analyze consumer behavior for a product design in an industrial design firm.
FIGURE 3: Diagram of physical layout of paper created during product design meeting.
In this non-computational arrangement, color (and kind) of paper and marker are used to visually reflect a notion of object type similar to that supported by Aquanet and improvised in the other systems. Objects shown in the diagram in Figure 3 have this information encoded in their shade of gray. While the majority of cards contain handwritten text, there are also some pictures and diagrams; these cards were assigned a different type because they were so visually distinct. As in the prior example from Aquanet, there is an apparent structure to this diagram. The cards on the top and to the left act as labels resulting in an incomplete matrix of lists. A distinct horizontal row of cards divides the matrix at its center. Annotations take the form of cards and Post-Its attached to or next to cards they discuss.
In summary, our data analysis uncovered sufficient regularity to support the idea that automatic recognition of implicit spatial structure was possible, and that it could identify several useful kinds relations.
FIGURE 4:Examples of primitive spatial structures.
FIGURE 5:Sample graphic layout.
The layout shown in Figure 5, a simplified version of the arrangement in Figure 1, contains seven individual objects of two distinct types. The initial structures, described using the spatial primitives, are two vertical lists of smaller light gray objects. These lists, in turn, are part of two instances of a composites type that consists of a larger darker gray object over a list of light gray objects. Because these are instances of the same type of composite and they are aligned, a horizontal list with two elements is the next result of the parse.
Figure 6 shows the final parse tree of the spatial layout from Figure 5. Non-terminal nodes of the graph reflect the primitive and intermediate structures that may be identified through analysis of spatial layout, including Horizontal list, Vertical list, and Composite. Terminal nodes show graphic depictions of the original types from the layout.
FIGURE 6:Spatial parse tree for sample layout.
The recognition algorithms were not tuned to any particular style of layout, and use only the location (x and y position), extent (width and height), and system-supplied type of the information objects. This limited set of characteristics was used so that the parser could be easily adapted to a variety of systems. For systems that do not include a notion of type, the visual characteristics of objects may be used to automatically assign them a type. This mapping of visual features to implicit object type is system dependent since different visual features are modifiable in different systems.
Using our survey examples as test cases, we found that this kind of parsing was fairly successful. At a low level, such as the labelled lists in Figure 1, the parser is quite accurate at determining what elements are part of the same structure; thus the small irregularities in alignment and spacing seem to be handled correctly. Ambiguous structures were not always identified as authors intended. For example, the fourth labelled list from the left in Figure 1 is identified as two separate lists (even though the author saw them as one) because of the large gap between the fragments.
Higher level structures were sometimes missed. For example, the six labelled lists in Figure 1 are parsed as two separate structures. In this example, the parser recognizes the first three lists as one structure, and the second three lists as another, because each of the lists on the left side of the diagram has an annotation directly above it. This is a second example of how layouts may also be ambiguous to humans without access to the semantics of the situation (if a reader did not realize the annotation functioned as such, he or she would make the same error as the parser). In most of our test cases, in spite of omissions and inaccuracies, the structure identified was often consistent with the authors' intent.
The strategist begins the recognition process by determining the order in which the pipeline of recognition specialists will be applied. This ordering is based on a statistical assessment of layout features. The specialists then begin a bottom-up parse of the layout; each specialist is responsible for identifying a particular type of structure. If the specialists define new types (as a result of encountering composites or heaps), they add these to the blackboard and recompute usage statistics to reflect the new structures. Figure 7 diagrams this process. The strategist, the blackboard, and recognition specialists are described in more detail below.
FIGURE 7:Architecture for spatial recognition.
First, they can help authors interact with ad hoc organization; the found structures can be used as the basis for supporting simple but repetitive information management tasks. Second, if a more formal knowledge base is a desired outcome of the task, recognizing structures is an important method for helping people notice and express the regular structure of their domain and maintain its consistency [15].
We are investigating these uses of the recognized structure in the context of VIKI [11]. With the addition of the spatial parser, VIKI assists authors in both interaction with ad-hoc structures and formalization of emerging structures. Before describing this support in detail we will give a brief overview of VIKI and its goals.
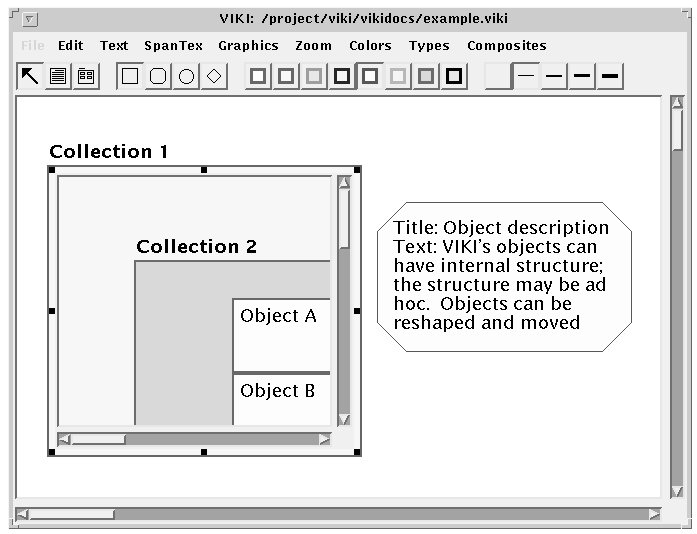
VIKI gives users the ability to work with three kinds of elements: objects, collections, and composites. Each graphical object is a visual symbol that refers to an underlying piece of semi-structured information. Each collection is a subspace that can reflect semantic categorization or a task-oriented subset of the information space. Composites are two or more objects which are used together to make up a meaningful higher-level unit of structure. These three kinds of elements allow users to build up the same kinds of structures we observed in practice. VIKI collections act as clipping regions so users can see information at multiple levels in the hierarchy of workspaces. Similar to Boxer [1], clicking on the border of a collection causes that collection to fill the VIKI window. Figures 8A and 8B show before and after images of collection traversal in VIKI.
FIGURE 8A: Screen A shows a VIKI collection acting as a clipping region prior to traversal.
FIGURE 8B Screen B shows the view after navigating into the collection.
VIKI uses the results of spatial parsing two ways: it supports interaction based on implicit structure (where implicit structure remains undeclared) and it helps people use the object-collection-composite data model by supporting the transition from implicit to declared structure. Examples of each of these uses are described below.
Click-selection in VIKI works much the same way as it does in a text editor. In a text editor, a single click puts the cursor at a particular point; the next click selects the word; the next, the paragraph; the next the entire document; and the next returns to the single point of selection. VIKI uses a similar technique: each successive click selects the next level of hierarchical structure.
Figure 9 Step 1. shows hierarchic click selection in action. The first click selects the individual object. The second click selects the list of three objects. The third adds the label for that list and the fourth selects a similar labelled list above the first list.
FIGURE 9: (Four figures below) Four steps in VIKI's recognition-based hierarchic click- selection.

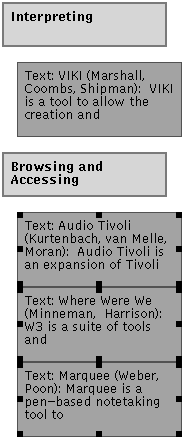

 FIGURE 9: (Four figures above) Four steps in VIKI's recognition-based hierarchic click-
selection.
FIGURE 9: (Four figures above) Four steps in VIKI's recognition-based hierarchic click-
selection.
Users realize two immediate advantages from hierarchic click-selection. First, users may select objects that are part of partially hidden structures without having to scroll or traverse from the current view. This is especially important in VIKI since collections act as clipping regions, displaying only portions of their contents. Thus, selecting a structure in one collection and moving it to another collection, a fairly frequent action, can be accelerated through use of click selection. Second, users may select partial structures in areas where objects are too densely packed for sweep- selection. In VIKI, such situations arise when users sort through large numbers of references to external documents--a frequent activity in the type of analysis tasks VIKI is designed to support.
In each of these cases, users tend to select objects this way for non-destructive operations, such as move, because the entire extent of the selection may not be visible.
Experiences with a variety of information management tools point to the difficulty users have in creating and using formal structure [16]. This difficulty led us to support a process of "incremental formalization", in which information is initially entered in an informal representation and later can be formalized when needed.
Incremental formalization aims, first of all, to eliminate the cognitive costs of formalization that inhibit user input. Secondly, it aims to reduce the burden of formalization by distributing it, and making it demand driven.
To further lower the cost of formalizing information, we are investigating techniques for using the recognized structure from the spatial parser to support incremental formalization. VIKI uses the results of the spatial parser to provide formalization suggestions to the user. This work builds on our experience with supporting incremental formalization based on the recognition of textual cues of inter-object relations in the Hyper-Object Substrate [17].
FIGURE 10:VIKI suggests a new collection based at the user's request.
To suggest collections in VIKI, we look for the highest level of contiguous structure. These higher level structures correspond to the task-oriented workspaces we observed in our survey. In determining which top- level structures to suggest as collections, structures which greatly overlap in space (and thus would obscure one another if made into collections independently) are combined. We limit the number of extraneous small collections that VIKI suggests by requiring a minimum number of constituent objects.
Collection suggestion uses a standard spelling checker as a model of interaction. In our interface, shown in Figure 10, the user can iterate through the list of suggestions and accept those that are appropriate. VIKI displays these suggestions to the user by selecting all objects and collections that will become part of the new collection and outlining its extent with a dark band. Users can modify suggestions by interactively changing which objects are selected and thus will be included in the new collection.
Users can ask for VIKI to suggest potential composite types from within the composite definition dialog. Users may either accept the suggestions as is, modify them, or start from scratch to develop new composite types. Figure11 shows the composite definition dialog with a suggested composite based on a recurrent pattern in the user's work. The suggestion appears as a set of abstract objects in an editable workspace with a composite name based on the names of the constituent objects and their arrangement.
FIGURE 11:Composite definition dialog with suggestion based on the structure shown in Figure 11.
Document analysis and recognition shares our goal of identifying structures implicit in the layout of information. It differs, however, in its emphasis on the recognition of presentational structures common to known genres rather than identifying the more dynamic, idiosyncratic structures that evolve in the process of manipulating information objects. Thus, while some basic techniques may be shared, they are apt to diverge due to this crucial difference.
Spatial recognition and parsing is also found in work on visual languages, but has different goals and assumptions which influence the types of recognition algorithms produced. Unlike Lakin's visual language parsing in vmacs [5], our algorithms do not assume that we can unambiguously recover their underlying syntactic structure. Unlike Pictoral Janus [3], a visual programming environment that bases connectivity on assessments of inside, connected, or touching, our purpose is not to "debug" formal visual/spatial structures, but rather to tease out some implicit partially-framed structure.
Our goal of providing better support for users' already apparent desire to work with implicit structure has influenced the spatial parser's design from the start. Saund's perceptually-supported sketch editor [13] and Moran's support using implicit structure in Tivoli [12], although focussing on recognition in pen-based sketches, are based on similar goals.
From our experience, it is apparent that new specialists are required for some kinds of recognition to proceed. Outlines, matrices and tables were found in our survey but are not parsed well by the current implementation.
Because of the idiosyncratic and ambiguous nature of the spatial structure, in cases where there is a high overhead for incorrect parses, interaction will be important in guiding this kind of recognition. Up to now, we have emphasized uses of recognized structure that are tolerant to inaccurate parsing; uses where the results are lightweight and used to provide alternatives for actions already possible through other means. Future work on interaction methods for correcting incorrect parses would be required before error-intolerant uses of recognized structure can be evaluated in real-use situations.
More generally, experience with enabling and supporting incremental formalization in VIKI shows promising results. This work leads to more issues to be explored in both methods of producing and interfaces to suggesting possible formalizations. We need more experience before we can answer questions like when suggestions should be provided to the user and what good interfaces are for providing such suggestions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}