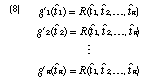Xerox Palo Alto Research Center
3333 Coyote Hill Road
Palo Alto, CA 94304
pirolli@parc.xerox.com
card@parc.xerox.com
To motivate previous designs of interactive information systems [6] , we appealed to mechanisms of cognitive science [5], and to general principles of information science [17] . We have argued that in an information-rich world, the real design problem to be solved is not so much how to collect more information, but rather, how to optimize the user's time, and we have deployed these principles in an attempt to increase relevant information gained per unit time expended. But for task analysis, design exploitation, and evaluation of information systems, a more developed theory is needed.
In this paper, we lay out the framework for an approach we call information foraging theory. This approach considers the adaptiveness of human-system designs in the context of the information ecologies in which tasks are performed. Typically, this involves understanding the variations in activity afforded by some space of human-system design parameters, and understanding how these variations trade-off the value of information gained against the costs of performing the activity. While complementary with information processing approaches to computer interaction theory, such as those in the GOMS family [5, 14], information foraging theory emphasizes a larger time-scale of behavior, the cost structure of external information- bearing environments, and human adaptation. Consider the time-scales of activity outlined by Newell [13] .
The sorts of information-seeking and sensemaking activities of interest to us span from the middle of the cognitive band of activity (~100 ms - 10 s), across the rational band (minutes to hours), and perhaps into the social band (days to months). Typically, information-processing models of cognition have addressed behavior at the cognitive band, and elementary cognitive mechanisms and processes (e.g., such as those summarized in the Model Human Processor, [5] ) play a large part in shaping observed behavior at that grain size. As the time scale of activity increases, "there will be a shift towards characterizing a system...without regard to the way in which the internal processing accomplishes the linking of action to goals" (Newell [13], p 150). Such explanations assume that behavior is governed by rational principles and largely shaped by the constraints and affordances of the task environment. Rather than assuming classical normative rationality, one may assume that the rationale for behavior is its adaptive fit to its external ecology [4] .
This is the essence of an ecological stance (Neisser, as cited in Bechtel [4]) towards cognition. Whereas information- processing models, such as GOMS, provide mechanistic accounts of how cognition operates, ecological models address why it operates that way, given the ecological context in which it occurs. This kind of integrated explanatory framework has been promoted by Marr [12] and, more recently, Anderson [1, 2] in cognitive science.
Information foraging refers to activities associated with assessing, seeking, and handling information sources. Such search will be adaptive to the extent that it makes optimal use of knowledge about expected information value and expected costs of accessing and extracting the relevant information. We use the term "foraging" both to conjure up the metaphor of organisms browsing for sustenance and to indicate a connection to the more technical optimal foraging theory found in biology and anthropology [21, 22]. Animals adapt their behavior and their structure through evolution to survive and reproduce to their circumstance. Essentially animals adapt, among other reasons, to increase their rate of energy intake. To do this they evolve different methods: a wolf hunts ("forages") for prey, but a spider builds a web and allows the prey to come to it. Humans seeking information also adopt different strategies, sometimes with striking parallels to those of animal foragers. The wolf-prey strategy bears some resemblance to classic information retrieval, and the spider-web strategy is like information filtering. Human hunter-foragers have been observed to hunt in groups when the variance of finding food is high. They accept a lower expected mean in order to minimize the probability of several days without food. Similarly, we have observed, in the field, professional market analysts who had developed an ethic of cross- referring information, essentially information-foraging in groups, so as to reduce the probability of missing important literature.
Optimal foraging theory is a theory that has been developed within biology for understanding the opportunities and forces of adaptation. We believe elements of this theory can help in understanding existing human adaptations for gaining and making sense out of information. It can also help in task analysis for understanding how to create new interactive information system designs.
Optimality models in general include the following three major components.
We assume that information foraging is usually a task that is embedded in the context of some other task and its value and cost structure is consequently defined in relation to the embedding task and often changes dynamically over time [3, 18]. The value of information [16] and the relevance of specific sources [18] are not intrinsic properties of information-bearing representations (e.g., documents) but can only be assessed in relation to the embedding task environment. Usually, the embedding task is some ill-structured problem for which additional knowledge is needed in order to better define goals, available courses of action, heuristics, and so on [15, 20]. Such tasks might include such things as choosing a good graduate school, developing a financial plan for retirement, developing a successful business strategy, or writing an acceptable scientific paper. The structure of processing and the ultimate solution are, in large part, a reflection of the particular knowledge used to structure the problem space. Consequently, the value of the external information may often reside in the improvements to the outcomes of the embedding task.
The use of optimality models should not be taken as a hypothesis that human behavior is classically rational, with perfect information and infinite computational resources. A more successful hypothesis about humans is that they exhibit bounded rationality or make choices based on satisficing [19]. However, satisficing can often be characterized as localized optimization (e.g., hill-climbing) with resource bounds and imperfect information as included constraints [23]. Optimality models do not imply that animals or information foragers will necessarily develop so as to embrace the simple optimum. Rather, they describe the possibilities of a niche, a possible advantageous adaptation if not blocked by other forces (for example, the consequences of another adaptation). For us, these models help fill in what Anderson [1] calls the Rational Level theory of information access.
We present several examples of foraging analyses to illustrate some of the range of problems and insights that may be addressed. Our coverage has to be limited, so we use three relatively concrete and detailed analyses from a particular system.
In the context of a an analysis of the Scatter/Gather document browser [9] we introduce two simple models, the information patch model, and the information diet model, borrowed rather directly from optimal foraging theory. These "conventional" models derive from Holling's disc equation [22], which states that rate of currency intake, R, is the ratio of net amount of currency gained (energy in the case of biological systems; information value in our case), U, divided by the total amount of time spent searching, Ts, and exploiting, Th,
TABLE OF EQUATIONS. Equation 1


TABLE OF EQUATIONS. Equation 2

The information patch model and the information diet model
are formulated as variants of Equation 2. We discuss the
analytic optimal solutions to these models in the context of
the illustrations.
We also develop a more comprehensive dynamic model that incorporates the information patch model and information diet model as subcomponents. Using dynamic programming we illustrate how one may determine the optimal human- system strategies using dynamic programming techniques.
A user's encounters with valuable or relevant information will typically have a clumpy structure over space and time. Information items are often grouped into collections such as libraries, databases, and wire services. The biological analogy is that an organism's ecology may have a variety of food patches of differing characteristics and the organism must decide how to best allocate its foraging time. Models of this situation are called patch models [7, 10, 22] .
We discuss an information patch model in the context of the Scatter/Gather text database browser.
Figure 1 presents a typical view of the Scatter/Gather interface. [Footnote1]. The emphasis in this browsing paradigm is to present users with a kind of automatically computed overview of the contents of a document collection, and to provide a method for navigating through this summary at different levels of granularity. This is achieved by organizing the collection into a cluster hierarchy.
Conceptually, a collection may be clustered, for instance, into B = 10 groups of related documents. Each cluster is represented by a separate area as in Figure 1. For each cluster, the user is presented with typical words that occur in the text contents of documents in a cluster, as well as the titles of the three most prototypical documents. The user may gather some subset of those clusters, by pointing and selecting buttons above each cluster, and then ask the system to scatter that subcollection into another B subgroups, by selecting a Scatter/Gather button at the top of the display in Figure 1. The clustering is based on a form of inter- document similarity computation based on representations of text contents. Scatter/Gather browsing and clustering employs methods that can occur in constant interaction-time [8].

FIGURE 1. The Scatter/Gather interface for navigation
through large document collections.
We can view Scatter/Gather clusters as information patches. Foraging in a cluster-patch corresponds to selecting a cluster, displaying the document titles belonging to the cluster in a scrollable window, scanning/scrolling through the listed titles, and for each title deciding if it is relevant or not to the query at hand. If the title is judged relevant, then it is handled by selecting, cutting, and pasting it to a query record window. Relevant and irrelevant documents will be randomly intermixed in the display window.
This simple loop of activity can be characterized by a cumulative gain function gi(t) that indicates how much information value is acquired over time t in cluster-patches of type i. In our empirical studies, we used specific task instructions that indicated that the information value was simply the number of relevant documents collected. The proportion of relevant documents in a cluster is the precision, P, of that cluster
TABLE OF EQUATIONS. Equation 3





 ,
,
 .
.
 ,
,  that maximizes the
currency intake rate R.
that maximizes the
currency intake rate R.